Your Guide to Text to Speech Voice Technology
Explore the complete guide to text to speech voice technology. Learn how AI voices are created, their uses, and how to get unlimited TTS with Verbatik.

Ever wondered what it would be like to have a personal narrator for your digital life? Someone who could read any article, email, or book aloud in a voice that sounds completely natural? That's exactly what modern text to speech voice technology delivers. It's a game-changing tool that turns written words into high-quality audio, making content more accessible and far more engaging.
What Is Text to Speech Voice Technology
At its heart, text to speech (TTS) technology is a digital storyteller. It takes any text you give it—a blog post, an e-book, a script for a video—and converts it into spoken word. But we’ve come a long way from the robotic, monotone voices that probably first come to mind. Today's systems use sophisticated AI to generate speech that is stunningly realistic and expressive.
This huge leap in quality comes down to deep learning. The AI models behind these voices are trained on massive datasets—we're talking thousands of hours of real human speech. This allows them to grasp not just the words themselves, but the nuances of human language like context, tone, and rhythm. The end result? A text to speech voice that can convey emotion, emphasize important points, and sound almost exactly like a human narrator. If you're curious about the nuts and bolts, you can get a closer look at how text to speech technology works.
The Evolution to Realistic Voices
The journey from clunky, computerized speech to the fluid, natural voices we have today is a massive milestone. It's about more than just better audio quality; it's about crafting a listening experience that is genuinely pleasant and effective. The difference between the old and new technologies is night and day.
Let's break down how far we've come.
The Evolution from Robotic to Realistic TTS Voices
| Feature | Traditional Robotic Voice | Modern Neural AI Voice |
|---|---|---|
| Sound Quality | Monotone, choppy, and obviously computerized. | Fluid, natural intonation, and emotionally expressive. |
| Pronunciation | Often struggled with complex words and names. | Handles difficult vocabulary and proper nouns with ease. |
| Pacing & Rhythm | Unnatural pauses and a steady, robotic cadence. | Mimics human speech patterns, including natural pauses. |
| Customization | Very limited; maybe a slight pitch or speed adjustment. | Highly flexible; control pitch, speed, emotion, and tone. |
| Underlying Tech | Concatenative (stitching pre-recorded sounds). | Neural networks and deep learning models. |
As you can see, the shift to neural AI voices has been a complete game-changer, moving TTS from a basic accessibility tool to a powerful creative one.
This side-by-side comparison shows just how close modern AI voices have gotten to human speech, while blowing past it in terms of speed and flexibility.
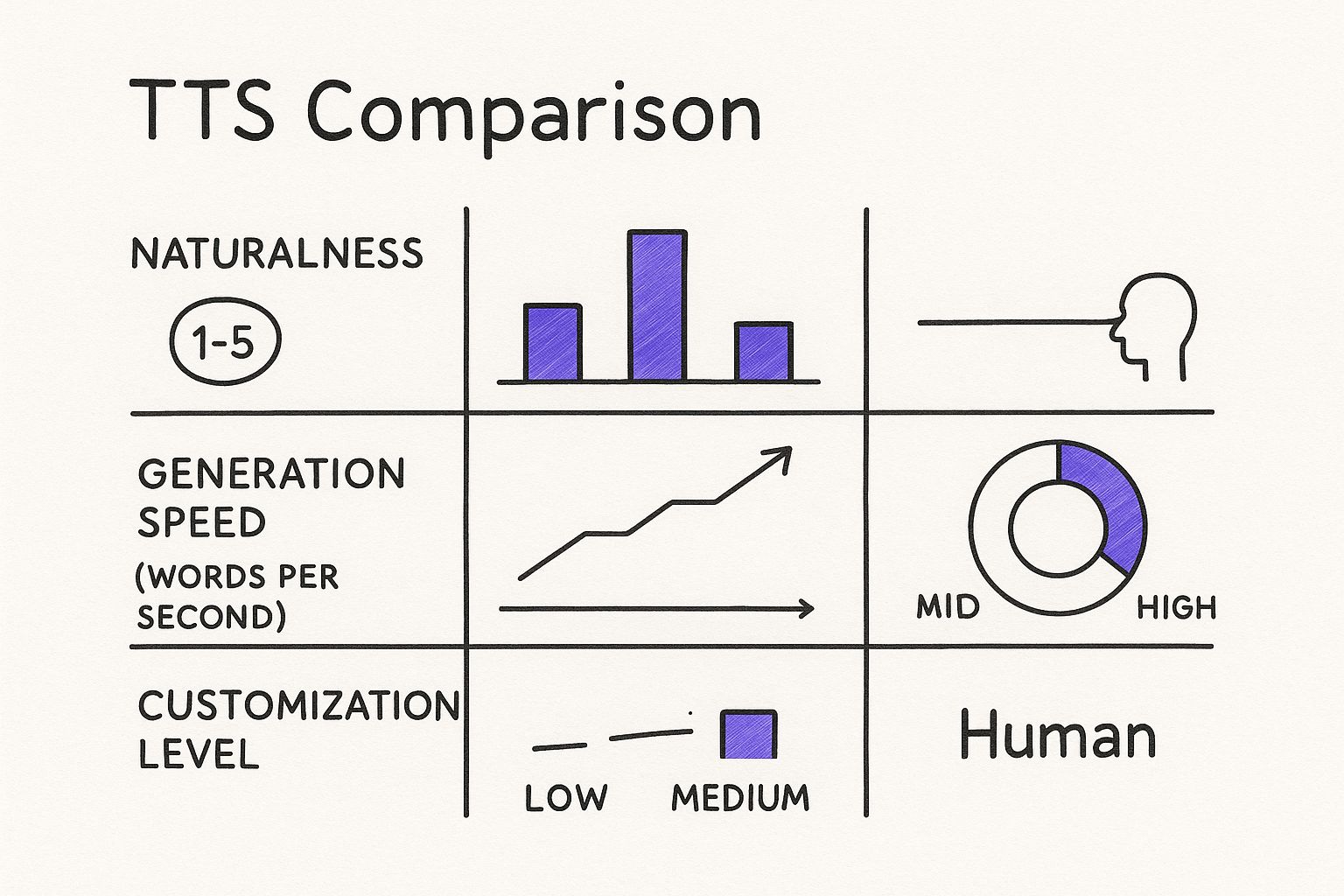
The chart makes it clear: while a real human voice still has a slight edge in pure naturalness, neural TTS offers incredible speed and customization, making it an incredibly versatile asset for anyone creating content.
Why This Technology Matters Now
This explosion in quality has lit a fire under the industry. In 2024, the global TTS market was valued at an impressive USD 4.55 billion, and it's projected to climb to an astonishing USD 37.55 billion by 2032. This growth isn't just a number—it reflects a massive, growing demand for audio content in practically every field imaginable.
For creators and businesses, this means audio is no longer an expensive, time-consuming luxury. It’s an accessible tool for expanding reach, improving accessibility, and creating dynamic content.
This shift has also made powerful platforms essential. To see how TTS fits into the bigger picture, it helps to understand the broader AI content generation landscape. An actionable insight here is to choose a platform that removes production limits. For example, a platform like Verbatik gives users unlimited text to speech and even voice cloning, which opens the door to producing massive amounts of studio-quality audio without character limits or sky-high costs. It's truly bringing advanced voice technology to the masses.
How AI Creates a Natural Sounding Voice
The jump from robotic, stilted speech to the smooth, expressive AI voices we hear today isn't some kind of magic trick. It's the result of some seriously clever artificial intelligence. The real secret is a technology called neural text to speech (NTTS), which relies on deep learning models to generate audio that sounds startlingly human.
Imagine an AI model as a method actor preparing for the role of a lifetime. But instead of a script, this actor is fed thousands of hours of recordings of actual human speech. It doesn't just memorize the words; it studies every subtle detail—the pitch changes, the tiny pauses between phrases, the emotional undercurrent, and the unique cadence of natural conversation.
This intense training process teaches the AI all the unwritten rules of language. It learns how a question mark changes the entire sound of a sentence or how certain words carry more weight. This is precisely what separates a modern text to speech voice from its clunky ancestors.
The Role of Neural Networks
At the heart of all this learning are neural networks, complex systems designed to operate a bit like the human brain. These networks sift through enormous amounts of audio data, picking out patterns in waveforms, phonetics, and prosody—the rhythm and sound of how we speak.
At first, the AI’s attempts at speech might sound like a jumbled mess. But with every try, it compares its own audio to the original human recordings and makes tiny corrections. This cycle, repeated millions of times, sharpens the AI's ability to produce speech that is clear, coherent, and emotionally authentic.
The goal isn't just about saying the words correctly. It's about delivering them with the right meaning and intent. This deep sense of context is what makes today’s AI voices so believable and engaging.
This advanced training is what allows platforms to offer powerful features. An actionable takeaway is that the underlying tech directly impacts your output. With a service like Verbatik, the result is the ability to generate unlimited text to speech or even create a perfect digital copy of your own voice through voice cloning. It’s this underlying tech that makes it all happen.
From Data to Dynamic Speech
Once the neural network is fully trained, it can generate brand-new speech from any text you give it. It’s not just gluing pre-recorded words together. Instead, it creates an entirely new audio waveform from scratch, predicting the most natural way to speak a sentence.
This predictive ability is what allows for real-time adjustments. Here’s how you can use this to your advantage:
- Pitch and Tone: Make a voice sound more authoritative for a news report or more empathetic for a storytelling podcast.
- Pacing and Speed: Slow things down for an e-learning course or speed it up for a high-energy ad.
- Emotional Style: Tell the AI to sound happy, sad, excited, or calm, adding another layer of realism to the performance.
This technology is getting better all the time, pushed forward by new research and huge market demand. One forecast expects the TTS market to hit USD 3.45 billion in 2024 and soar to USD 28.02 billion by 2034. This explosive growth shows just how vital TTS has become for everything from entertainment to building more inclusive digital experiences. You can learn more about the growth of the text-to-speech market.
The incredible progress in this space is well-documented. If you want to dive deeper, you can explore the full evolution of text to speech technology, which follows the journey from the first synthesized sounds to the lifelike AI voices we have now. This transformation has opened up a world of possibilities for creators and businesses everywhere.
Choosing the Right AI Voice for Your Project
Picking the perfect text to speech voice for your content is a lot like casting an actor for a movie. The voice you choose sets the entire mood, builds a connection with your audience, and can be the deciding factor in how your message is received.
Let's be honest, not all AI voices are created equal. A high-energy, upbeat voice that's perfect for a YouTube intro would feel completely jarring in a serious corporate training video. This is why having a diverse library of voices isn't just a nice-to-have feature; it's essential for finding the right audio identity for your brand.
Matching the Voice to the Purpose
Before you even start listening to voice samples, take this actionable step: define what this audio needs to accomplish. Are you teaching, entertaining, informing, or selling? Each goal demands a completely different vocal style.
An e-learning course, for instance, needs a voice that is exceptionally clear, well-paced, and professional. The entire point is for people to understand and remember information, so a steady, authoritative tone works wonders. On the flip side, a podcast or an audiobook needs a voice with genuine warmth and emotional range to keep a listener hooked for the long haul.
The most effective AI voice doesn't just read words; it conveys the intended emotion and purpose behind them. Your choice directly influences listener engagement and the overall perception of your brand.
This is where having the freedom to experiment really pays off. A service like Verbatik gives you unlimited text to speech generation across a massive library, so you can try out different voices—friendly, serious, or even a quirky character voice—without worrying about hitting a limit. You can test and tweak until you find the one that just clicks with your audience.
The Importance of Variety and Global Reach
Today’s audiences are spread all across the globe, and your audio content should be too. Sticking to a single, generic American or British accent can instantly alienate listeners from other regions. This is where multilingual support and authentic regional accents become your secret weapon.
Using a British English voice for a UK-based marketing campaign or a Spanish voice with a native Mexican accent for a tutorial aimed at that market adds a powerful layer of authenticity. It’s a small detail that tells your audience you understand and respect them.
Here’s a quick rundown of the main voice categories you'll encounter:
- Standard Male and Female Voices: These are your go-to, versatile options for things like corporate narration, announcements, and most general-purpose content.
- Child Voices: Perfect for children's educational content, animated stories, or any project that needs a youthful, innocent tone.
- Character Voices: These are highly specialized voices designed for creative projects. Think video games, cartoons, or unique ad campaigns that need a standout personality.
- Multilingual and Accented Voices: Absolutely critical for localizing your content and building a real connection with international audiences.
The best tools make it easy to sort through these options to find exactly what you need, fast.
Matching Voice Type to Content Purpose
To make this even clearer, here’s a simple table to help you match the right kind of voice to your project's goals.
| Content Type | Recommended Voice Type | Primary Goal |
|---|---|---|
| Corporate Training Video | Standard (Clear, Professional) | Education & Information Retention |
| Podcast / Audiobook | Standard (Warm, Expressive) | Engagement & Entertainment |
| Children's E-Learning | Child Voice (Friendly, Upbeat) | Engagement & Simple Comprehension |
| Video Game Character | Character Voice (Distinct, Emotional) | Immersion & Storytelling |
| Global Marketing Ad | Multilingual / Accented | Authenticity & Connection |
As you can see, the "best" voice is all about context. The right choice makes your message more effective and memorable.
Actionable Tips for Voice Selection
Simply picking a voice from a list is just the start. The real magic happens when you start fine-tuning its delivery. Great text-to-speech platforms let you adjust the pitch, speed, and emphasis to get the performance just right.
Here are a few practical steps to follow:
- Define Your Audience Persona: First, picture who you're talking to. What's their age, location, and what kind of tone do they expect? This will immediately help you narrow down the right gender, age, and accent.
- Test Multiple Voices: Never settle for the first voice you hear. Generate a short clip of your script with 3-4 different voices. Listen to them back-to-back and see which one best captures the feeling you're going for.
- Clone a Unique Voice: For total brand consistency, nothing beats voice cloning. This process lets you create a custom text to speech voice that is 100% unique to you, ensuring all your audio content sounds instantly recognizable.
The market is full of great tools, but they all have different strengths. To see how the top platforms compare, check out our in-depth guide on the best text to speech tools for 2025. In the end, taking the time to choose the right voice will make your content more engaging, accessible, and impactful.
Unlocking Personalization with Voice Cloning
Ready to move beyond generic AI narrators? Voice cloning is an actionable strategy to create a text to speech voice that’s a dead ringer for a real human speaker—maybe even your own. This isn't just about reading words; the technology captures the unique quirks, tone, and emotion of a person's voice to produce a digital replica.
For any brand or creator, this is a game-changer. It’s a powerful way to build a memorable audio identity. With Verbatik's unlimited text to speech and voice cloning, you can finally craft a consistent sound for your brand, no matter how much content you're producing.
- Authentic Sound: Perfectly replicate your own voice or the familiar tone of a brand ambassador.
- Scalable Output: Generate thousands of voiceovers without racking up studio fees.
- Consistent Branding: Ensure your audio sounds the same everywhere, from ads to tutorials.
Unlike picking from a list of pre-set TTS voices, a clone gives you complete ownership of your audio brand. Imagine your CEO narrating new product launches or internal training videos, all without ever stepping into a recording booth. It’s a massive win for every team.
How Voice Cloning Works
So, how does this actually happen? Voice cloning uses machine learning to turn a short audio recording into a personalized, endlessly usable voice model. It all starts with you recording a quick voice sample in a quiet place.
From there, the AI gets to work. It breaks down the recording, analyzing everything from phonetics and pitch to rhythm and pacing. It learns what makes that voice unique. Once the analysis is done, it builds a synthetic model that can generate brand new speech from any text you give it.
- Record a quick 1–2 minute sample using a decent microphone.
- Upload that audio file right into Verbatik’s cloning interface.
- Let the AI process the data and train the new voice model.
- Use your new clone to generate unlimited audio.
The processing time can vary a bit, but most clones are ready to go within 30 minutes. Before your model is activated, a few verification steps ensure the audio is clear and, most importantly, that you’ve given consent. Your privacy is paramount; voice samples are encrypted and only stored with your permission, protected by strict data controls.
Benefits for Branding Consistency
Having a single, recognizable voice across all your podcasts, ads, and video tutorials is incredibly powerful for brand recall. When people hear that familiar voice, it builds trust and creates an emotional connection.
It's also a huge time-saver. Instead of trying to coordinate schedules with different voice actors, you have your own dedicated announcer on call 24/7.
"Voice cloning is the secret ingredient for brands seeking a distinctive and unified audio presence."
And these cloned voices aren't stuck in one language. You can maintain your signature vocal style while speaking Spanish, Mandarin, or dozens of other languages. Think about it:
- Podcast intros always in your brand's voice.
- On-hold phone messages with a consistent, professional tone.
- Personalized customer notifications that sound familiar across every channel.
Implementing consistent audio cues like these can boost brand recall by as much as 25%. In a crowded market, a custom voice helps your message cut through the noise.
Getting Started with Your Own Clone
Creating your own custom voice model is surprisingly simple. Once you've recorded your sample, the AI does all the heavy lifting. You'll get back a clone that you can immediately start tweaking with different pitch and pacing settings to get it just right.
Here’s a peek at Verbatik’s voice cloning page, which shows just how straightforward the upload and customization process is:

As you can see, the dashboard is designed to be user-friendly, and you can even preview your new voice in real time.
Want to go deeper into the tech? Check out our deep dive article on voice cloning.
To get the best results, keep these tips in mind:
- Use a quiet environment for your recording to keep the sample clean.
- Read from a consistent script to give the AI good, uniform data to learn from.
- Adjust the rate and pitch of the final voice to match your brand's personality.
- Experiment with different emotional styles to see what your audience responds to.
You don't need any technical expertise to get started. Just follow the prompts in the Verbatik dashboard. Fine-tuning the emotional tone alone can increase listener engagement by up to 33%.
When you pair voice cloning with unlimited TTS, you never have to worry about hitting a cap on audio generation. You can iterate, experiment, and refine your brand’s voice as much as you want.
Once your clone is live, it’s easy to integrate it into your daily workflows for customer support, video narration, and dynamic ad creation. The end result is a hallmark audio identity that makes your brand stand out and keeps all your content perfectly aligned.
Practical Applications for AI Voices
The real magic of a text to speech voice isn't in the tech itself—it's in the actionable strategies you can deploy with it. This technology has moved way beyond simple narration and is now solving real problems for businesses and creators everywhere. From making content to handling customer support, AI voices are becoming a go-to tool for communicating better and faster.
Content production is one of the biggest areas feeling this shift. Actionable insight: you can now produce an entire audiobook or a podcast series without ever stepping foot in a recording studio or hiring a voice actor. This is a game-changer. Creators can feed a long script into a tool and get back high-quality audio, slashing production time and costs. It frees them up to focus on what matters most—the content itself.
You see this efficiency in video creation, too. YouTubers and social media managers can whip up a clean, professional voiceover in minutes. Instead of spending hours recording, re-recording, and editing their own voice, they can get narration that instantly boosts the quality of their videos and keeps their audience hooked.
Scaling Content for a Global Audience
For companies with a worldwide reach, a text to speech voice is the fastest path to localization. Suddenly, e-learning courses, product demos, and internal training materials can be voiced in dozens of languages almost instantly. This ensures everyone, whether they're in Tokyo or Toronto, gets a consistent and easy-to-understand experience.
This ability to scale also transforms automated customer service. AI-driven Interactive Voice Response (IVR) systems can now offer callers helpful information in a friendly, natural voice—a massive upgrade from the clunky, robotic recordings of the past. These new systems can handle more calls more effectively, letting human agents tackle the truly complex problems.
The real strategic advantage here is the ability to create huge volumes of high-quality audio without the old-school bottlenecks of time and money. This is where unlimited generation becomes a massive asset for growth.
For example, platforms like Verbatik offer unlimited text to speech and voice cloning, which means you never have to worry about hitting a character limit. Businesses can scale their audio content with confidence, whether it's for a single ad campaign or a whole library of training videos. To see how this plays out, you can check out some smart strategies for leveraging text-to-speech technology for business growth.
Emerging and Creative Use Cases
The use cases for AI voices just keep growing, especially in creative fields. Podcasting has been completely re-energized. You can now easily turn your notes into a podcast with AI, giving written content a second life and reaching people who prefer to listen instead of read.
Here are a few more powerful applications that are gaining ground:
- Accessibility Overlays: Websites can add TTS functionality to read content aloud, making the web far more accessible for users with visual impairments or reading challenges like dyslexia.
- Gaming: Indie game developers can now afford to have dynamic dialogue and narration for their characters, adding a layer of polish that was once reserved for big-budget studios.
- Real Estate: Imagine a virtual property tour where a pleasant voice describes the features of each room as you navigate. That’s now possible, creating a much more immersive experience for potential buyers.
The market is exploding because of this widespread adoption. One report estimated the global TTS market at USD 4.0 billion in 2024, with projections showing it could hit USD 7.6 billion by 2029. This boom is powered by constant AI improvements and the smart devices we all use daily. At the end of the day, the versatility of a modern text to speech voice makes it an essential tool for anyone wanting to be heard in our audio-first world.
Got Questions About TTS? We've Got Answers.
As you get more familiar with text to speech voice technology, you're bound to have some questions. It’s a powerful tool, and understanding the details is key. Let's clear up a few of the most common things people ask.
Just How Real Can a Text to Speech Voice Sound?
Honestly, it's pretty staggering. Modern neural text to speech voices can sound so realistic they're often completely indistinguishable from a human speaker. The stiff, monotone robot voices from a decade ago? They’re ancient history.
Today's AI has been trained on thousands of hours of high-quality human speech, so it understands the little things that make us sound human—natural intonation, proper pacing, and even emotional inflection. It can deliver a story with warmth, a training module with authority, or an ad with genuine excitement. For any kind of professional work, this level of quality isn't just nice to have; it's essential.
What’s the Deal with "Unlimited Text to Speech"?
Unlimited text to speech is a total game-changer, especially for creators. It means you can convert as much text as you want into audio without ever hitting a character limit or getting charged by the word. You just pay a flat subscription fee, so your costs are completely predictable.
Think about what that unlocks. You could produce an entire audiobook, a full season of a podcast, or all the voiceovers for a huge e-learning course. With a service like Verbatik, "unlimited" gives you the freedom to create and experiment without constantly watching the meter. It's a huge advantage for anyone producing audio at scale.
Is It a Hassle to Clone My Own Voice?
Not anymore. Voice cloning used to be complex and expensive, but now it's incredibly straightforward and accessible. You definitely don’t need a recording studio or a sound engineering degree to create a perfect digital copy of your voice.
The process is usually just a few simple steps:
- Record a Quick Sample: You'll read from a script for a few minutes. Just find a quiet room and use a decent microphone—your phone's mic can even work in a pinch.
- Upload the Audio: Drag and drop your recording into the platform’s cloning tool.
- Let the AI Do Its Thing: The AI gets to work analyzing everything that makes your voice unique—your pitch, tone, and rhythm—and builds a custom voice model from it.
Platforms like Verbatik have made this incredibly easy, even offering unlimited voice cloning with their plans. It’s a powerful way to build a unique audio brand that is always, recognizably you.
Can I Use These Voices for Commercial Projects?
Yes, absolutely. Most professional-grade text to speech platforms are built for commercial use and give you full rights to the audio you generate, especially on their paid plans. This means you can legally use the AI voices for any content you plan to monetize.
This covers all the big ones:
- YouTube videos that have ads
- Paid online courses and corporate training
- Audiobooks sold on sites like Audible
- Podcasts that feature sponsorships
- Digital ads for radio, streaming, or social media
Of course, you should always give the terms of service a quick read for any platform you use. But reputable providers design their services with commercial creators in mind, giving you the legal confidence you need. This is another scenario where an unlimited text to speech plan shines, letting you create huge volumes of commercial content without costs spiraling out of control.
A quick heads-up: while the tech is easy to use, licensing terms can vary. Always double-check that you have the rights to use the audio for your specific commercial goals. A few minutes of reading now can save you from legal headaches down the road.
Getting this right from the start ensures you can scale your projects without hitting any roadblocks, turning your great ideas into successful ventures.
Article created using Outrank


